I've worked with many teams to deliver large distributed operational systems that, during development, required obtaining specific types of business data from other parts of the enterprise. Too often, the team has to resort to discovering a data source that suits their requirements — they may know about other subsystems but not how to obtain the necessary data. They search repos, browse database servers, analyze schema, etc. Their only available criterion is whether tables, columns, and fields have names similar enough to what they're looking for.
NOTE
For this post, I'll refer to a particular type of business information, an entity. You might not use that term, and that's fine.
An entity is an object that has an identity and a life cycle. An entity maintains its identity through various states and changes to its attributes throughout its life cycle. An entity has consistency rules that govern its state (the value of its attributes) and how the state may change.
Although I've worked with teams that discovered data sources many times, doing this is problematic. I get involved in dealing with the problems that result, maybe you've encountered them as well:
- You have to make multiple request to different data sources to get a complete view of an entity.
- Some data has invalid or unsupported values requiring transformation or enrichment to be compatible with downstream systems.
- Requests to the data source sometimes fail because the expected structure of the request or response has changed without warning.
- The data source has high latency or is unable to support the load, resulting in
429 Too Many Requestserrors. - The received information includes sensitive information that your system should not have access to causing security concerns.
- Decisions stall because technical stakeholders disagree on whether the data source is "correct" while providing no alternatives.
The disadvantage of discovering an appropriate data source is that it is based solely on the physical structure of a database (the name and types of columns and the relationships between them, i.e., the schema). A schema describes implementation well, but cannot communicate intent to discern fit-for-purpose accurately. While you can get the data points you need, you don't know if that's the intended purpose of this data source and its data points. Making decisions without knowing intent often leads to issues we'll describe shortly, the biggest being not knowing if the data source will be supported as long as you need it. The intent of the provided data points could not have taken into account your app's needs. As a result, you can't be sure what you're getting is actually what you need. In some cases, a data source doesn't have all the data points you need.
It's tempting to accept a data source that doesn't have all the data points you need, especially if you can get the remaining data points from another data source. With no single data source providing a complete view of the entity, multiple data sources often have overlapping information, which is, by definition, duplicate data. This introduces another dilemma: what should happen if two duplicate data points have different values? The bigger issue with this method of hydrating an entity is the inherent race condition that accessing duplicate data involves. Data duplicated across sources is data whose updates are uncoordinated, resulting in an unaligned view of the entity. This unaligned view can lead to read tearing, e.g., both data sources A and B updated information related to a particular entity, but your system retrieved information from A before the update and B after the update, and your system is now responsible for detecting the problem and taking corrective action. Writes across data sources are non-atomic, resulting in a fictitious (inconsistent) view of the entity.
INFO:
Conflicts between transactions (non-atomic updates) is a common concurrency scenario. This scenario has many established solusions, like optimistic concurrency control implemtnations such as HTTPsETagandIf-*headers.
In addition to these data sources not providing a true view of the entity, discovered data sources couldn't have implemented all the consistency rules that your system may depend on. Independent of the above race conditions, this leaves your system liable for detecting entities in an inconsistent state and taking corrective action. This unconstrained data means performing translation, doing transformations, or enriching the data received from these data sources. Unconstrained data also means forever playing catch-up with all unpredictable inconsistencies as they appear, and the possibility that no corrective action can fix some without intervention.
The fact that a data source exists indicates that it serves some purpose, unaligned with yours. Services, software, information, and data are products. Products, like entities, endure over time, evolving and changing. The reasons and schedule by which discovered data sources evolve are independent of the system you're trying to develop. The independent evolution of pre-existing data sources will cause adverse effects on your system. For example, data sources may need to change their interface or schema for reasons unbeknownst to you. These changes may cause sudden catastrophic failure or hard-to-find data inconsistency issues. Issues arising from changes in an upstream data source never designed to support your system will not occur on your terms.
Using a discovered data source means becoming an unintended client of the data source. That may be fine; most services can tolerate traffic fluctuations. But that system has not accounted for traffic from your system. If you're maintaining an SLA for your system, your reliability target will now depend on the reliability of these data sources. Without knowing what reliability targets they have, you will no longer be able to commit to your reliability targets. You may get reliability targets for these data sources, and if those reliability targets are below yours, you'll have to adjust yours. You could spend time collaborating with all the data sources to improve their reliability targets. Alternatively, you may have to throttle your use of the data source by naively caching, which can introduce issues with out-of-date data and cache invalidation.
INFO - Calculating Effective Reliability
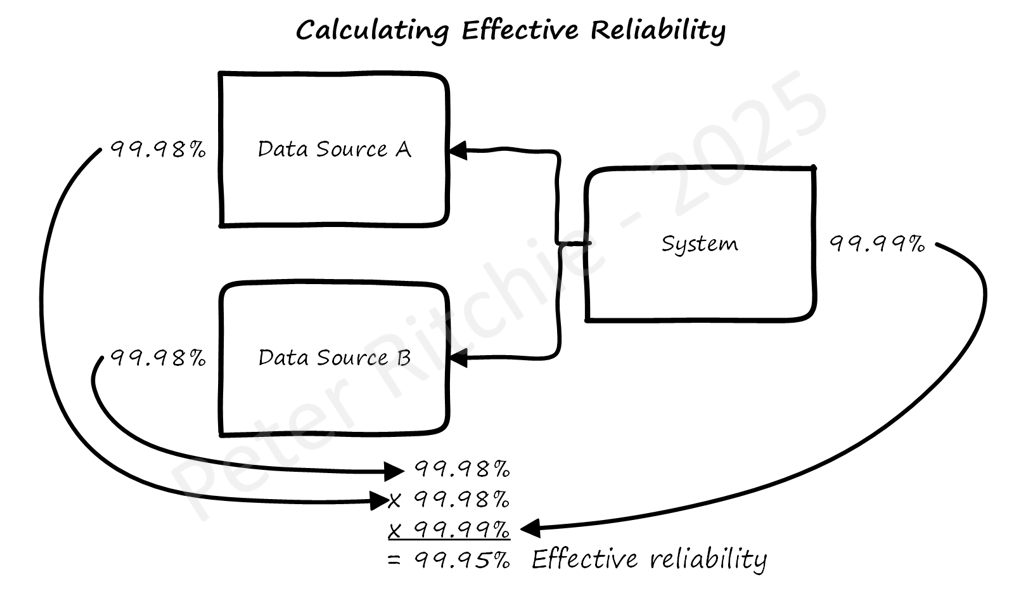
Authentication will be data source specific, with different authorization than what your system provides (i.e., service versus user). A different authorization scope could accidentally authorize access to sensitive data (like internal, confidential, or restricted data). It may not seem like a big deal; you're not using it, right? But all the information you receive has to pass through the infrastructure and frameworks your system uses. Infrastructure and frameworks process this data, and some of that processing is logging. If you're not expecting sensitive information, your system isn't handling it correctly. A SecOps review can raise security "recommendations" that will be very difficult to remediate. You might even have to discover an alternative source.
After encountering or avoiding all the above scenarios, you might still feel justified in using discovered data sources. Your system's deployment to and use of infrastructure should catch the attention of people responsible for established data sensitivity and performance policies. This attention can lead to an evaluation of the architectural decision to use the discovered data source. That evaluation might result in feedback like "you shouldn't be using that data source for that" when you think you're about to deliver a solution. My experience has been that often alternatives are not provided, leaving you to deal with the consequences.
Systems of Record
The approach I recommend—instead of discovering data sources and all the disadvantages that come with it—is to design a System of Record for that type of business information.
A System of Record captures, validates, updates, and stores authoritative records for a specific type of business entity. A System of Record is an operational data source (not directly used for reporting or analytics) because its focus is on recording the outcome of business transactions upon entities.
There are a couple of approaches realizing a System of Record. In the case of a discovered data source (that contains all the necessary datapoints), someone can propose that the discovered data source take on the responsibility of being a system of record for that business entity. If an existing candidate isn't available, someone can propose creating a new system that takes on the responsibility of being a system of record for that business entity. Organizations need to manage Systems of Record as products. Products endure over time, have contractual agreements with clients/customers, respond to evolving needs and environments, etc.
A System of Record should:
- have clear, accountable ownership.
- provide operations to correctly, reliably, and robustly capture and update an entity.
- authorize and audit the operations performed on an entity.
- be interoperable with downstream and analytical systems.
- focus on operational data, isolating it from analytical data.
have clear, accountable ownership.
A System of Record has a clear intent and scope to manage specific entity information (realizing the subsequent attributes of a System of Record). It needs to have a dedicated development team, business owner, etc. (i.e., have a "Product Charter" and the executive sponsorship to empower it)
provide operations to correctly, reliably, and robustly capture and update an entity.
All the business rules around modifications and validation are the responsibility of the System of Record, ensuring accurate, complete, and validated information through durable and isolated operations.
authorize and audit the operations performed on an entity.
The integrity of business information needs to be maintained, preventing unauthorized and conflicting updates. The source of updates to information should be forensically analyzable. Systems of Records must adhere to regulatory and retention policies when updating information.
be interoperable with downstream and analytical systems.
The structure and format of information provided by a System of Record should be the standard by which all downstream systems align, ensuring interoperability.
focus on operational data, isolating it from analytical data.
I've touched on "reporting" and "analytics" above, but I want to be very clear about how important it is to separate operational systems from analytical systems. Don't get me wrong, analytical data is based on operational data, but operational data involves effectively-atomic business transactions upon individual entities ("effectively" atomic because they need to appear atomic, but implementation in distributed systems means transaction state is sometimes persisted in a database and shared across processes). Organizations must make analytical data available intentionally. E.g., aggregations involve many entities across periods (like monthly rollups), and an ETL process must aggregate data only once per period. ETL processes must support multiple independent Systems of Record.
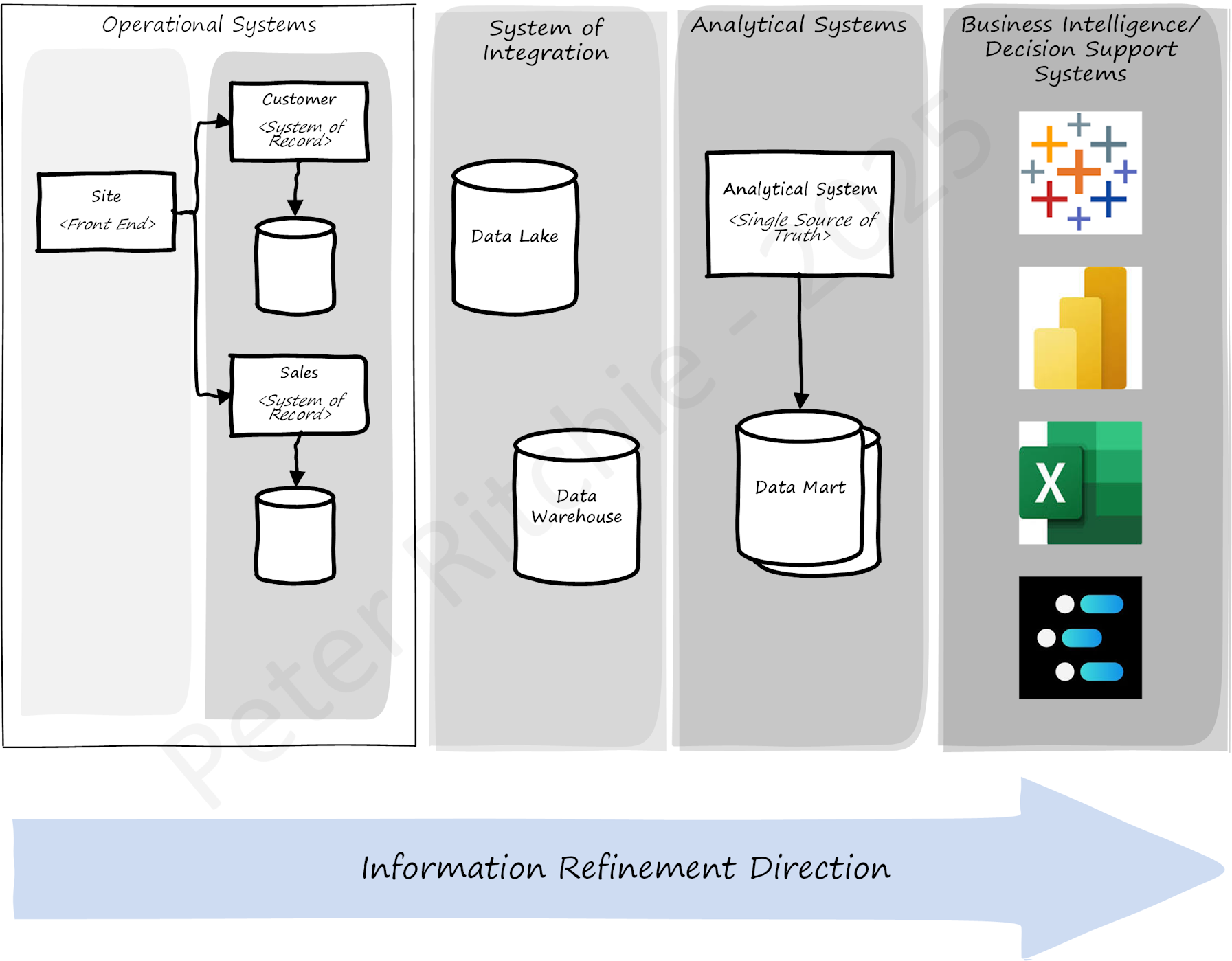
I hope this post conveys that any-old-data source is not good enough and that persisting and maintaining business information deserves attention in order to provide useful software systems.
comments powered by DisqusIf you find this useful
I'm a freelance software architect. If you find this post useful and think I can provide value to your team, please reach out to see how I can help. See About for information about the services I provide.